X岛揭示板
搜索
时间线
综合线
创作线
非创作线
亚文化线
综合2线
游戏线
生活线
综合
综合版1
DANGER/U/
欢乐恶搞
速报2
绘画(二创)
社畜(校园)
故事(小说)
都市怪谈(灵异)
军武
技术宅(代码)
数码(装机)
宠物
女装(时尚)
买买买(物品推荐)
亚文化
动画综合
漫画
婆罗门一
电影/电视
主播管人(圈内)
卡牌桌游
特摄(布袋戏)
战锤
胶佬(手办)
铁道厨(车辆)
VOCALOID
小马(美漫)
东方Project
舰娘
创作
跑团
创作茶水间
规则怪谈
海龟汤(推理)
科学(干货)
文学(推书)
音乐(推歌)
AI(Chatgpt)
摄影(cos)
ROLL点
游戏
游戏综合
手游专楼
任天堂
N
S
腾讯游戏(LOL)
暴雪游戏
SE(FF14)
V社(DOTA)
怪物猎人
鹰角游戏
米哈游
音游打卡
联机(服务器发布)
生活
露营
育儿
自救互助
料理(美食)
体育(健身)
学业打卡
日记(树洞)
管理
值班室
技术支持
版务
三百人委员会
功能
用户系统
我的订阅
我的发言(new)
手机版
普通版
首页版规
|
用户系统
|
移动客户端下载
|
丧尸路标
|
|
常用图串及路标
| 请关注 官方公众号:
【X岛揭示板】
官方微博:
【@X岛极速版】
|
人,是会思考的芦苇
常用串:·
豆知识
·
跑团板聊天室
·
公告汇总串
·
X岛路标
X岛揭示板
学业打卡
第 4 页
登录
学业打卡
名 称
管理员
E-mail
标题
颜文字
正文
附加图片
水印
•欢迎各路学霸考王互触
•可以询问备考问题、日西考试成绩
•本版发文间隔15秒
无标题
无名氏
2025-10-01(三)15:20:47
ID:dAGEZKM
[
举报
]
[
订阅
]
No.67145586
[
回应
]
管理
管理 -> No.67145586
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
努力学习
回应有 219 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
dAGEZKM
2026-03-31(二)13:01:29
ID:AHd0IKr
[
举报
]
No.68398927
管理
管理 -> No.68398927
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
等体检
…
无标题
无名氏
2026-03-31(二)17:15:48
ID:AHd0IKr
[
举报
]
No.68401219
管理
管理 -> No.68401219
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
刚好事业编统考也出分了,招一排三,去雷达上把分放出来改个名吧,同岗加油(ゝ∀・)
…
无标题
无名氏
2026-06-03(三)23:20:02
ID:AHd0IKr
[
举报
]
No.68774861
管理
管理 -> No.68774861
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
准备体检
…
无标题
无名氏
2026-06-04(四)12:21:56
ID:AHd0IKr
[
举报
]
No.68777488
管理
管理 -> No.68777488
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
希望顺利(=゚ω゚)=
…
无标题
无名氏
2026-06-12(五)00:26:25
ID:AHd0IKr
[
举报
]
No.68833697
管理
管理 -> No.68833697
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
明天审之,希望顺利(=゚ω゚)=
无标题
无名氏
2025-05-24(六)12:30:39
ID:siDG29y
[
举报
]
[
订阅
]
No.66149925
[
回应
]
管理
管理 -> No.66149925
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
重生之我在抖音当大v
做了一段时间的自媒体,在这里记录下账号的数据
回应有 202 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
无名氏
2026-02-15(日)11:12:50
ID:siDG29y
(PO主)
[
举报
]
No.68088880
管理
管理 -> No.68088880
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
>>No.68087676
卡灯牌给粉丝画头像之类的?
可能会涨粉
或者
把把自己的画画过程加上一些很糖的语音发成视频
…
无标题
无名氏
2026-02-15(日)11:14:36
ID:siDG29y
(PO主)
[
举报
]
No.68088889
管理
管理 -> No.68088889
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
>>No.67939445
不过你其他平台都是万粉了
那其实也侧面证明你的思路没啥问题嘛
只是可能抖音的受众不同
我觉得没必要死磕
百花齐放固然美好
但一枝独秀也不算啥坏事嘛
…
无标题
无名氏
2026-06-08(一)01:42:35
ID:siDG29y
(PO主)
[
举报
]
No.68802511
管理
管理 -> No.68802511
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
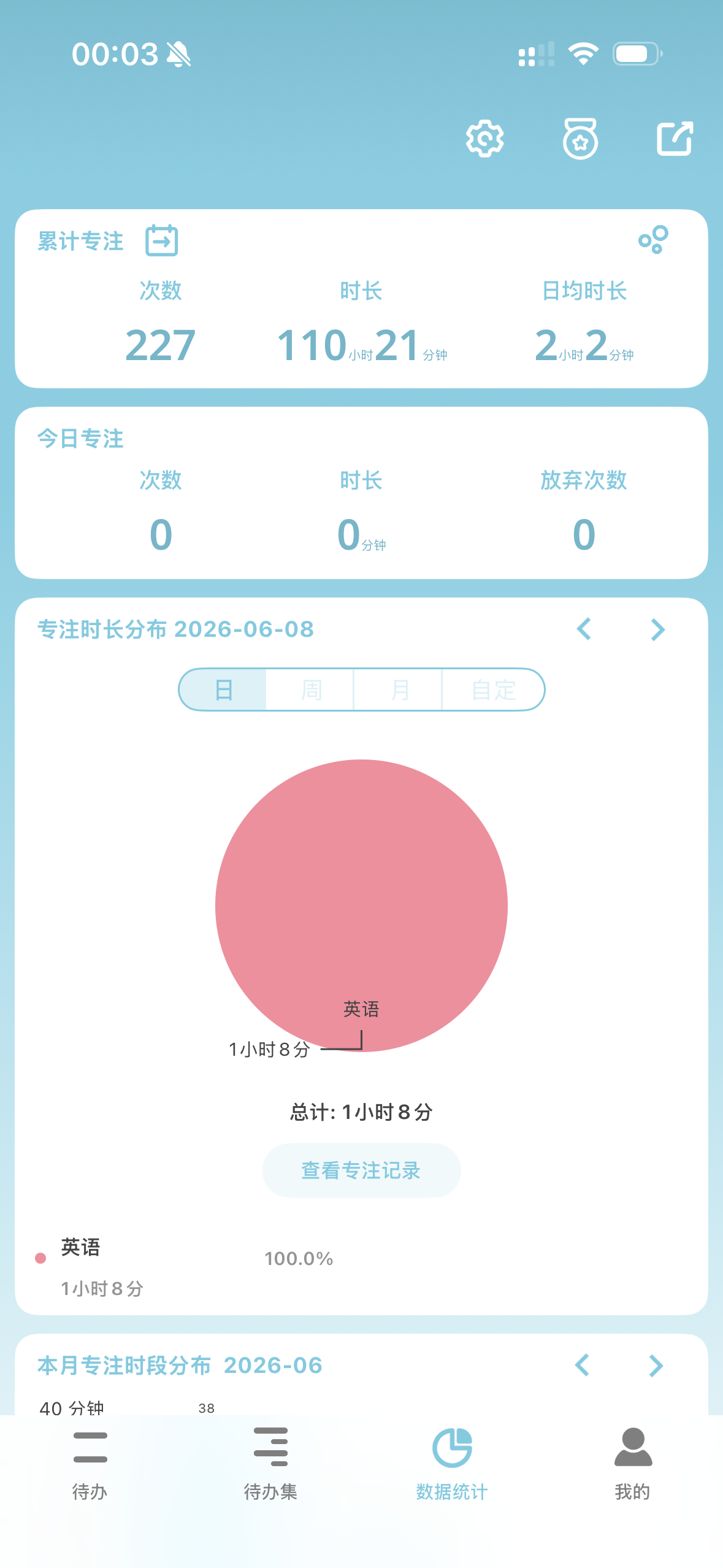
2026.06.08 点赞:1.3w 粉丝:4048
——
历史许久……终于四千粉了
…
无标题
无名氏
2026-06-08(一)02:02:35
ID:dQvpKMt
[
举报
]
No.68802599
管理
管理 -> No.68802599
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
祝贺!
…
无标题
无名氏
2026-06-11(四)16:37:02
ID:QkDAXXC
[
举报
]
No.68829906
管理
管理 -> No.68829906
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
恭喜(*´∀`)
无标题
无名氏
2026-06-11(四)00:29:46
ID:5GB6JUg
[
举报
]
[
订阅
]
No.68825776
[
回应
]
管理
管理 -> No.68825776
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
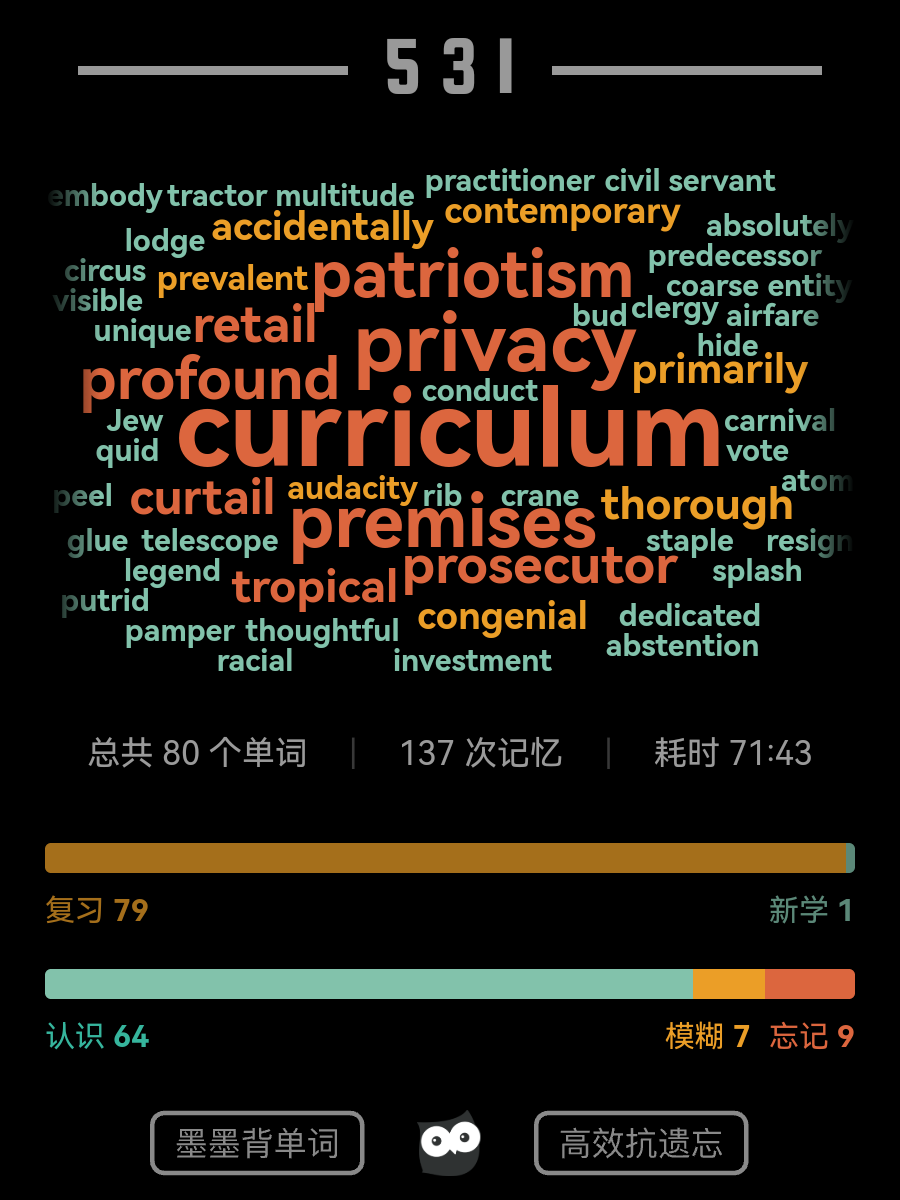
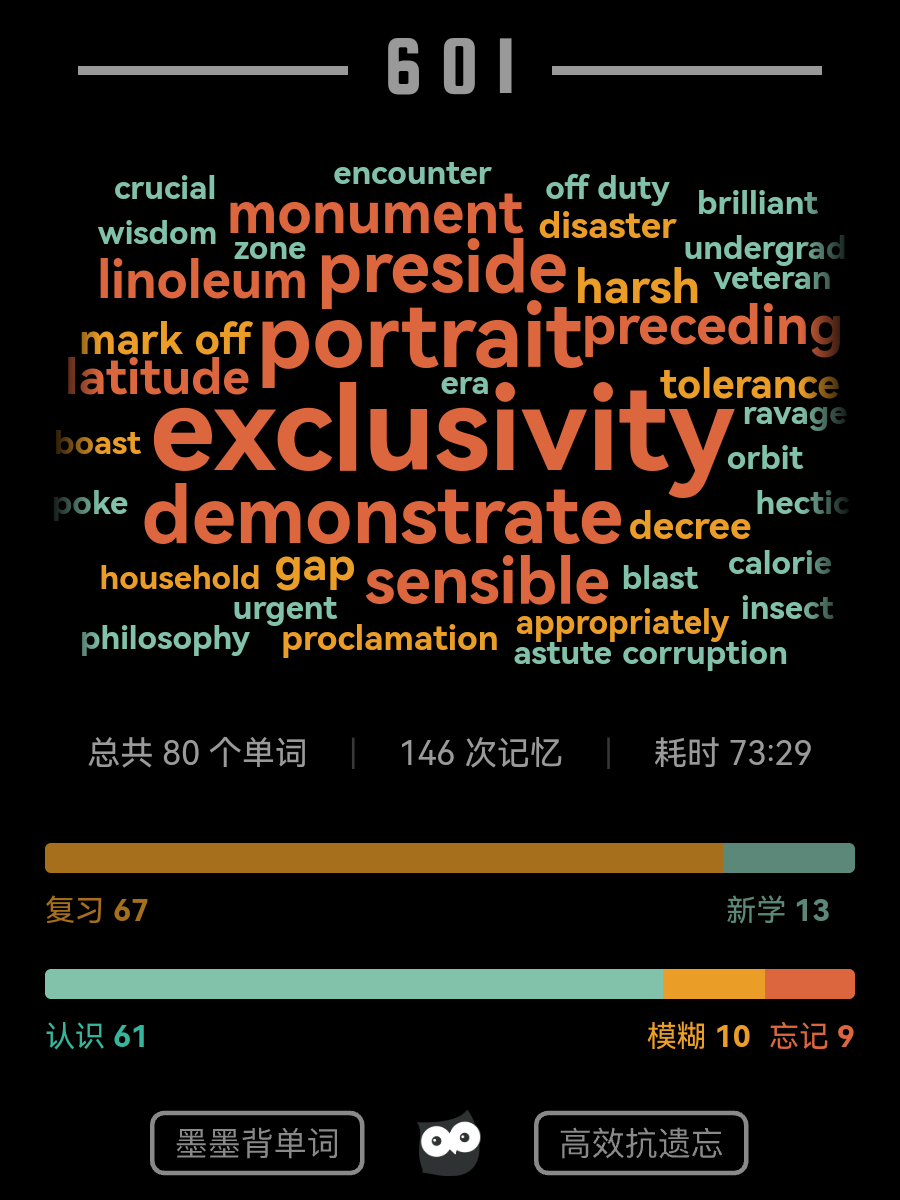
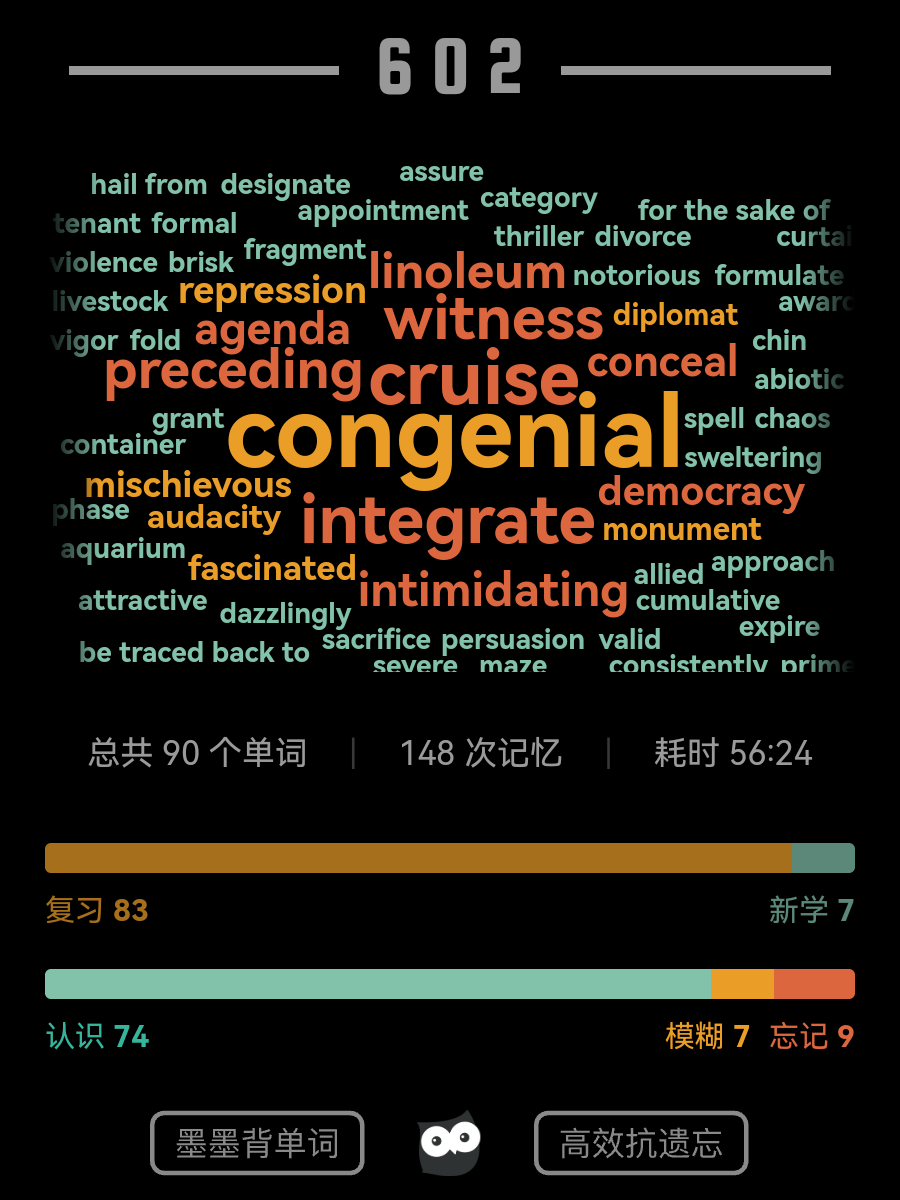
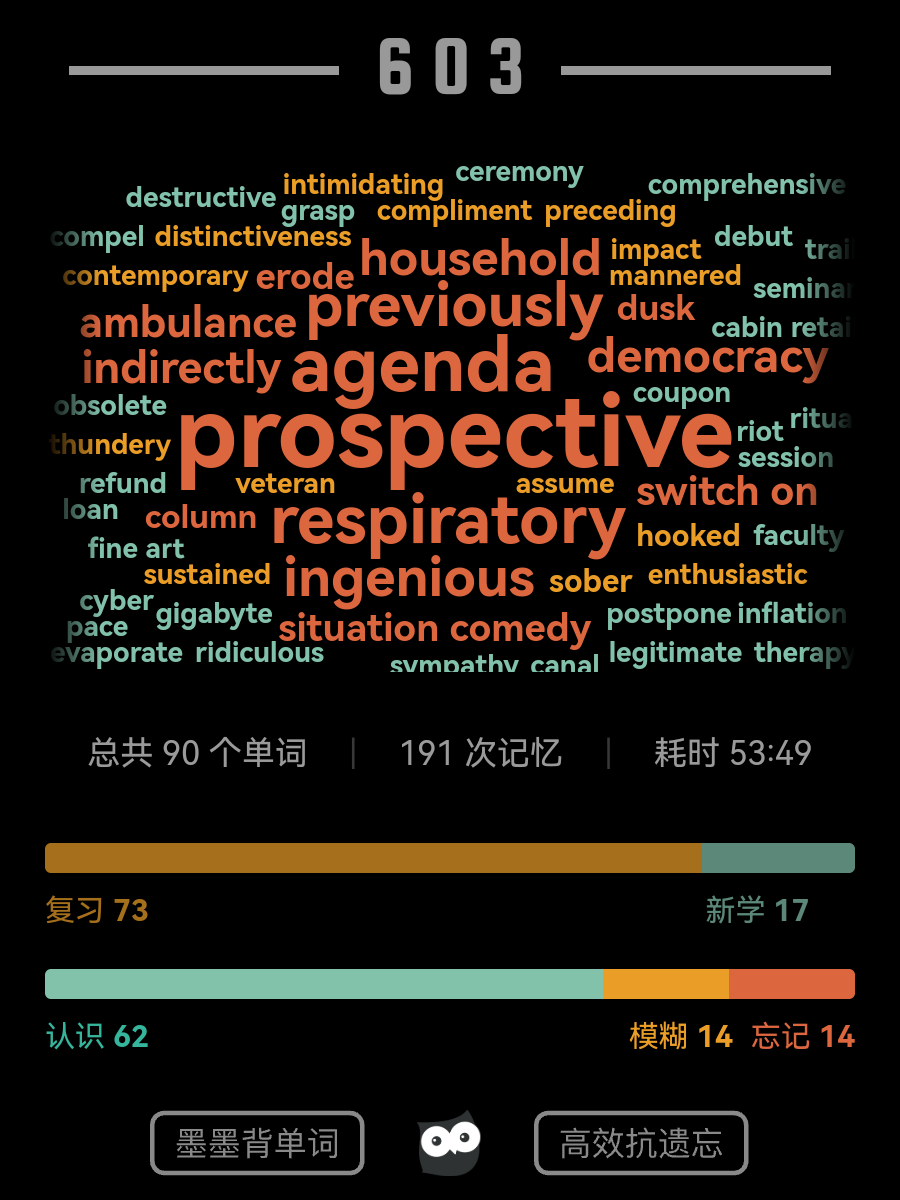
早期背单词串
…
无标题
无名氏
2026-06-11(四)08:13:28
ID:uM6pLXZ
[
举报
]
No.68826772
管理
管理 -> No.68826772
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
po快起来呀,不要睡了| ω・´)
无标题
无名氏
2026-06-11(四)00:44:38
ID:5GB6JUg
[
举报
]
[
订阅
]
No.68825875
[
回应
]
管理
管理 -> No.68825875
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
六点早起背单词打卡
…
无标题
无名氏
2026-06-11(四)02:29:47
ID:cYcwrZc
[
举报
]
No.68826331
管理
管理 -> No.68826331
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
本来不想记饼的,但学业版都是你的串很难不注意呢(`ヮ´ )
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-06-10(三)21:51:26
ID:5GB6JUg
[
举报
]
[
订阅
]
No.68824475
[
回应
]
管理
管理 -> No.68824475
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
今天起算是准高三生了每天来打卡写心得
回应有 5 篇被省略。要阅读所有回应请按下回应链接。
本串已经被SAGE (
?
)
…
无标题
无名氏
2026-06-11(四)00:39:21
ID:qKuWMaK
[
举报
]
No.68825832
管理
管理 -> No.68825832
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
??我是不是看过这个串( ˇωˇ)
…
无标题
无名氏
2026-06-11(四)00:41:57
ID:CM2LNdM
[
举报
]
No.68825848
管理
管理 -> No.68825848
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
onp,你这唐人被骂了还挨个举报到值班室,是不是觉得自己还是受害者啊( ^ω^)
…
无标题
无名氏
2026-06-11(四)00:43:09
ID:OJlgoHd
[
举报
]
No.68825858
管理
管理 -> No.68825858
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
( ^ω^)
…
无标题
无名氏
2026-06-11(四)02:21:42
ID:cYcwrZc
[
举报
]
No.68826310
管理
管理 -> No.68826310
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
祝考上心仪的大专呢
…
无标题
无名氏
2026-06-11(四)02:24:58
ID:cYcwrZc
[
举报
]
No.68826318
管理
管理 -> No.68826318
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
要我说,与其玩300多天进厂还不如现在入职进厂呢(。◕∀◕。)
无标题
无名氏
2026-06-10(三)16:56:33
ID:yuFDWN7
[
举报
]
[
订阅
]
No.68822251
[
回应
]
管理
管理 -> No.68822251
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
哦,对
高考结束了。
…
无标题
无名氏
2026-06-10(三)16:58:54
ID:DciPG79
[
举报
]
No.68822268
管理
管理 -> No.68822268
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
你是高中教师还是高
考完把你大学录取证书发出来看看不然你就还是高(^o^)ノ
…
无标题
无名氏
2026-06-10(三)17:08:34
ID:hTl3YHe
[
举报
]
No.68822327
管理
管理 -> No.68822327
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
如果是考完了的准大学生就先玩几天呗(*゚∇゚)
无标题
无名氏
2026-06-10(三)16:13:11
ID:Y9PYzVb
[
举报
]
[
订阅
]
No.68821819
[
回应
]
管理
管理 -> No.68821819
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
期末考核为小组作业,组员1劝说多次死性不改遇事就打开ai,组员2连插入文本编辑格式都不会未知之前论文是如何写完的,现在离交作业只有12天了,心如死灰( ^ω^)
无标题
无名氏
2026-03-04(三)00:46:41
ID:PWhCaTk
[
举报
]
[
订阅
]
No.68205509
[
回应
]
管理
管理 -> No.68205509
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
27考研( `д´)σ
再不开始就要来不及了啊(;´Д`)
回应有 146 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
无名氏
2026-06-01(一)22:48:58
ID:PWhCaTk
(PO主)
[
举报
]
No.68759610
管理
管理 -> No.68759610
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
实习Day44
同上
…
无标题
无名氏
2026-06-02(二)22:43:39
ID:PWhCaTk
(PO主)
[
举报
]
No.68767730
管理
管理 -> No.68767730
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
实习Day55
同上
最后一天实习
…
无标题
无名氏
2026-06-05(五)12:15:03
ID:PWhCaTk
(PO主)
[
举报
]
No.68784929
管理
管理 -> No.68784929
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
回家了,躺了两天,先准备六级
…
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-06-09(二)00:05:16
ID:PWhCaTk
(PO主)
[
举报
]
No.68810098
管理
管理 -> No.68810098
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
Day57
好久没做六级题了,复健一下,先从听力开始
…
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-06-10(三)00:20:06
ID:PWhCaTk
(PO主)
[
举报
]
No.68817645
管理
管理 -> No.68817645
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
Day58
无标题
无名氏
2026-04-04(六)22:43:28
ID:FIv41fK
[
举报
]
[
订阅
]
No.68428562
[
回应
]
管理
管理 -> No.68428562
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
4.16要交论文初稿那么问题来了我到底能不能按时写完呢
回应有 19 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
无名氏
2026-04-19(日)04:28:58
ID:FIv41fK
(PO主)
[
举报
]
No.68511429
管理
管理 -> No.68511429
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
>>No.68501342
谢谢肥哥(〃∀〃)
此串将在
本月底更新修改进度;
5月中老师给评语以后的继续修改+准备答辩进度( ´_ゝ`)
现在先让我玩两星期再说ᕕ( ᐛ )ᕗ
…
无标题
无名氏
2026-05-26(二)05:00:01
ID:FIv41fK
(PO主)
[
举报
]
No.68714816
管理
管理 -> No.68714816
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
我回来了,带着新鲜出炉(十几天前拿到)的评语( ゚∀。)
6.3答辩 我还有9天修改+准备ppt+准备讲稿
…
无标题
无名氏
2026-05-28(四)22:09:50
ID:FIv41fK
(PO主)
[
举报
]
No.68734169
管理
管理 -> No.68734169
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
前几天修了格式,做了图和表,改完大部分正文里小修改的部分,写了致谢,做了附录,没想到格式要花这么久改,word我恨你(╬゚д゚)
今天应该把conclusion的大修改写完,还有这个abstract我是真写不出来好想丢给AI。。。
…
无标题
无名氏
2026-06-03(三)20:14:14
ID:FIv41fK
(PO主)
[
举报
]
No.68773840
管理
管理 -> No.68773840
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
我答辩完了ᕕ( ᐛ )ᕗ
但是老师提出了新的小修改。然后abstract还是没写出来( ›´ω`‹ )
…
无标题
无名氏
2026-06-09(二)22:12:01
ID:FIv41fK
(PO主)
[
举报
]
No.68816585
管理
管理 -> No.68816585
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
我交了(ノ゚∀゚)ノ脱离苦海!
虽然课还没上完还没法正式毕业,好多麻烦的文件和手续( ›´ω`‹ )
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-06-09(二)20:57:29
ID:JbhdPU9
[
举报
]
[
订阅
]
No.68815986
[
回应
]
管理
管理 -> No.68815986
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
这里是一个文科研二并且已经荒废学业将近两个月的废物一个。
考博没有方向,考公舍友已经学完了资料分析而我一笔没动,故决定开始打卡,明天开始能学一点是一点。
同样情况的肥哥也可以一起鼓励。( ゚ 3゚)
…
无标题
无名氏
2026-06-09(二)20:59:25
ID:JbhdPU9
(PO主)
[
举报
]
No.68815998
管理
管理 -> No.68815998
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
因为专业原因这个月要准备去调研。
下周准备去开介绍信,这周就先把已经整理好的资料收拾收拾,连着初稿一起弄一弄。
…
收起
查看大图
向左旋转
向右旋转
Day0
无名氏
2026-06-09(二)21:01:30
ID:JbhdPU9
(PO主)
[
举报
]
No.68816011
管理
管理 -> No.68816011
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
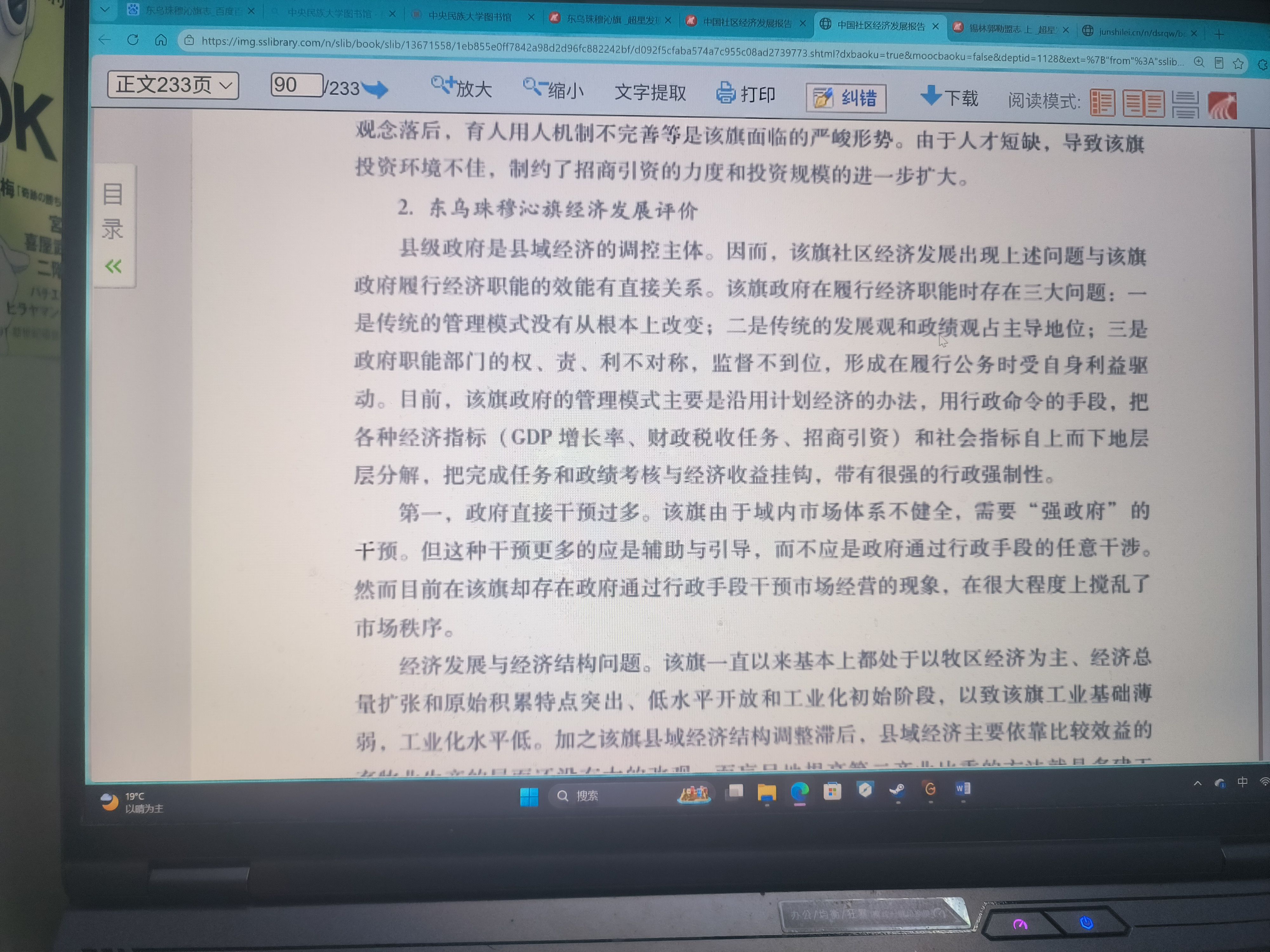
今天实际上和过去两个月一样没怎么看题,但也在稍微调整自己的状态。
阅读《中国社区经济发展报告》
找了调研点有关的经济发展情况,但遗憾的是和过去看的大部分资料一样只有基础情况,从硕士毕业论文角度来看基本没有出新点,也只能先摘录下来,方便到时候继续撰写。
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-06-07(日)02:37:06
ID:uH2Q8Qc
[
举报
]
[
订阅
]
No.68796099
[
回应
]
管理
管理 -> No.68796099
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
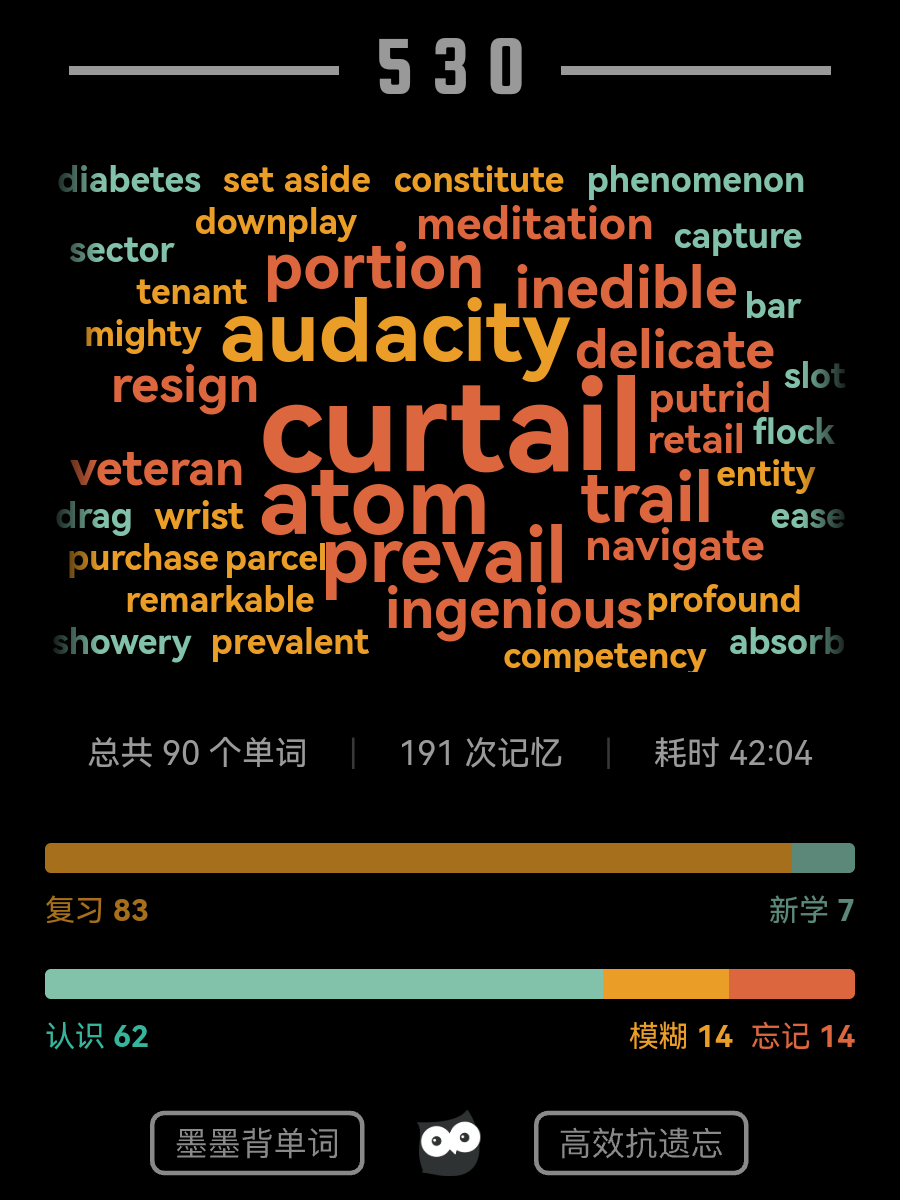
我竟然把5000多个单词都复习完了,想要举高高
回应有 2 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
无名氏
2026-06-07(日)08:19:24
ID:yXENcor
[
举报
]
No.68796598
管理
管理 -> No.68796598
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
_∧_∧_
((∀`/ )
/⌒ /
/(__ノ\_ノ(((ヽ
(_ノ  ̄Y\
| (\ (\ /) | )举高高!
ヽ ヽ` ( ゚∀゚ ) _ノ /
\ | ⌒Y⌒ / /
|ヽ · | · ノ //
\トー仝ーイ
| ミ土彡/
). \ ° /
( \. y \
…
无标题
无名氏
2026-06-07(日)10:14:55
ID:OH4kNiY
[
举报
]
No.68796922
管理
管理 -> No.68796922
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
_∧_∧_
((∀`/ )
/⌒ /
/(__ノ\_ノ(((ヽ
(_ノ  ̄Y\
| (\ (\ /) | )举高高!
ヽ ヽ` ( ゚∀゚ ) _ノ /
\ | ⌒Y⌒ / /
|ヽ · | · ノ //
\トー仝ーイ
| ミ土彡/
). \ ° /
( \. y \
…
无标题
无名氏
2026-06-07(日)19:43:37
ID:568VA21
[
举报
]
No.68800259
管理
管理 -> No.68800259
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
_∧_∧_
((∀`/ )
/⌒ /
/(__ノ\_ノ
(_ノ ||| 举高高~~
∧_∧ ∧_∧
(( ・∀・ ))・∀・) )
`\ ∧ ノ
/ |/ |
(_ノ_)_ノL_)
…
无标题
无名氏
2026-06-09(二)04:07:08
ID:hZtVaH6
[
举报
]
No.68810869
管理
管理 -> No.68810869
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
真拿你没办法| ω・´)
_∧_∧_
((∀`/ )
/⌒ /
/(__ノ\_ノ
(_ノ ||| 举高高~~
∧_∧ ∧_∧
(( ・∀・ ))・∀・) )
`\ ∧ ノ
/ |/ |
(_ノ_)_ノL_)
…
无标题
无名氏
2026-06-09(二)16:26:46
ID:09Ssze6
[
举报
]
No.68813803
管理
管理 -> No.68813803
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
_∧_∧_
((∀`/ )
/⌒ /
/(__ノ\_ノ(((ヽ
(_ノ  ̄Y\
| (\ (\ /) | )举高高!
ヽ ヽ` ( ゚∀゚ ) _ノ /
\ | ⌒Y⌒ / /
|ヽ · | · ノ //
\トー仝ーイ
| ミ土彡/
). \ ° /
( \. y \
无标题
无名氏
2022-09-09(五)15:52:08
ID:QfZ7t5q
[
举报
]
[
订阅
]
No.51875920
[
回应
]
管理
管理 -> No.51875920
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
大四的倒霉蛋们可能有的已经开始写毕业论文了哇。
这个串是专门给只希望混毕业的小笨蛋开的,论文混过去的指导|∀゚
毕竟肥肥我啊,论文全是借鉴的|∀゚
然后你猜多少分|∀゚
85嘿嘿|∀゚
总之跟着这个串走,只要你不是大笨蛋,都能过的(`・ω・)
回应有 799 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
无名氏
2025-12-18(四)06:20:55
ID:9lYa9vf
[
举报
]
No.67671768
管理
管理 -> No.67671768
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
这个串我去年毕业的时候还真用上了,感谢( ´∀`)
…
无标题
无名氏
2026-02-07(六)23:29:17
ID:awtI3gf
[
举报
]
No.68032997
管理
管理 -> No.68032997
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
挖| ω・´)
…
无标题
无名氏
2026-02-09(一)03:01:42
ID:C6exTnn
[
举报
]
No.68041089
管理
管理 -> No.68041089
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
顶一下
…
无标题
无名氏
2026-02-09(一)03:10:27
ID:rkKTZwg
[
举报
]
No.68041098
管理
管理 -> No.68041098
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
( ´∀`)谢谢学姐,常看常新。之前看还用不上。今年终于轮到我了
…
无标题
无名氏
2026-06-08(一)15:06:56
ID:jFClhxL
[
举报
]
No.68805882
管理
管理 -> No.68805882
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
存一手,谢谢学姐(〃∀〃)
无标题
无名氏
2026-03-04(三)17:21:08
ID:S5kr05k
[
举报
]
[
订阅
]
No.68209850
[
回应
]
管理
管理 -> No.68209850
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
27考研串来( ´_ゝ`)
回应有 33 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
无名氏
2026-04-01(三)00:13:38
ID:S5kr05k
(PO主)
[
举报
]
No.68404922
管理
管理 -> No.68404922
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
>>No.68404905
当然大学之后就再也没玩过这一出了(;´ヮ`)7
…
无标题
无名氏
2026-04-10(五)00:35:04
ID:S5kr05k
(PO主)
[
举报
]
No.68459724
管理
管理 -> No.68459724
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
今日战绩
学习论文(1/1)
学习mathematica(1/1)
电磁学(0.5/1)
数理(0/1)
我踏马回来了( `д´)
我草我真得跪谢毕业论文的老师,学了一下发现自己根本不可能搞得完这个毕业论文,但是老师给我掏了一篇上届学长的毕业论文,只是计算方法不一样,研究对象基本是一样的,也就是说我可以照着抄(`ε´ )
爱你罗哥,明天见
…
无标题
无名氏
2026-04-12(日)23:24:00
ID:S5kr05k
(PO主)
[
举报
]
No.68476055
管理
管理 -> No.68476055
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
今天没学,肥适之你怎能如此。
开始夜间档学习( `д´)
…
无标题
无名氏
2026-05-08(五)09:48:32
ID:HFV8smg
[
举报
]
No.68607949
管理
管理 -> No.68607949
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
po你你快继续加油啊(;´Д`)
…
无标题
无名氏
2026-06-07(日)03:27:17
ID:S5kr05k
(PO主)
[
举报
]
No.68796209
管理
管理 -> No.68796209
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
>>No.68607949
玩的有点嗨,在忙毕业,明天一定开始学( ´_ゝ`)
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-02-22(日)12:09:19
ID:Caeieis
[
举报
]
[
订阅
]
No.68133340
[
回应
]
管理
管理 -> No.68133340
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
一键快进到毕业( `д´)σσσ[快进]
回应有 248 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
无名氏
2026-05-16(六)18:44:43
ID:Caeieis
(PO主)
[
举报
]
No.68655391
管理
管理 -> No.68655391
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
下下周答辩,快解放了
…
无标题
无名氏
2026-05-21(四)11:08:49
ID:Caeieis
(PO主)
[
举报
]
No.68684153
管理
管理 -> No.68684153
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
肝这学期最后一个PPT( ´_ゝ`)
…
无标题
无名氏
2026-06-06(六)11:46:32
ID:Caeieis
(PO主)
[
举报
]
No.68791584
管理
管理 -> No.68791584
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
毕业啦——!!
…
无标题
无名氏
2026-06-06(六)16:09:05
ID:568VA21
[
举报
]
No.68792769
管理
管理 -> No.68792769
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
_∧_∧_
((∀`/ )
/⌒ /
/(__ノ\_ノ
(_ノ ||| 举高高~~
∧_∧ ∧_∧
(( ・∀・ ))・∀・) )
`\ ∧ ノ
/ |/ |
(_ノ_)_ノL_)
…
无标题
无名氏
2026-06-06(六)19:54:52
ID:Caeieis
(PO主)
[
举报
]
No.68794164
管理
管理 -> No.68794164
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
>>No.68792769
|∀` )好耶——!
无标题
无名氏
2026-06-05(五)20:20:27
ID:vzmHAue
[
举报
]
[
订阅
]
No.68788303
[
回应
]
管理
管理 -> No.68788303
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
28三战法考( `д´)9
…
无标题
无名氏
2026-06-05(五)20:21:05
ID:vzmHAue
(PO主)
[
举报
]
No.68788306
管理
管理 -> No.68788306
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
其实还是27,不过到法考的时候就是28了|∀` )
无标题
无名氏
2026-05-25(一)16:41:00
ID:9MQ6bYM
[
举报
]
[
订阅
]
No.68711470
[
回应
]
管理
管理 -> No.68711470
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
也许是一个医学生实习打卡串
不安,焦虑,抑郁
回应有 6 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
无名氏
2026-05-29(五)15:50:32
ID:9MQ6bYM
(PO主)
[
举报
]
No.68738196
管理
管理 -> No.68738196
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
新消息来了,让我们可以走了( ゚∀。)
什么意思( ゚∀。)
…
无标题
无名氏
2026-06-01(一)16:14:19
ID:9MQ6bYM
(PO主)
[
举报
]
No.68757091
管理
管理 -> No.68757091
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
day1
没人管我们( ゚∀。)
消化老师都好忙,让我们自个找地方玩去了(不是)
看群聊里有同学哀嚎第一天就开始跟手术连跟三台中午还不管饭( ゚∀。)
爽摸了一天鱼( ゚∀。)
在办公室看书好刺激
…
无标题
无名氏
2026-06-02(二)19:53:42
ID:9MQ6bYM
(PO主)
[
举报
]
No.68766626
管理
管理 -> No.68766626
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
day2
依旧没人管实习
稀里糊涂查了房然后稀里糊涂跟着回到办公室……
然后开始看书( ゚∀。)
…
无标题
无名氏
2026-06-04(四)08:35:12
ID:GDIfIen
[
举报
]
No.68776156
管理
管理 -> No.68776156
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
围观( `ー´)
…
无标题
无名氏
2026-06-04(四)08:42:38
ID:hX2ZxTZ
[
举报
]
No.68776183
管理
管理 -> No.68776183
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
po加油啊,我也在考研,不过我们的实习到是很宽松,老师也比较通情达理,大多数时候早上露个面就可以回去看书了
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-04-07(二)11:38:59
ID:WQ5KAon
[
举报
]
[
订阅
]
No.68441155
[
回应
]
管理
管理 -> No.68441155
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
考研打卡串
我这样的肥肥也可以上岸吗(*゚ー゚)
回应有 25 篇被省略。要阅读所有回应请按下回应链接。
…
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-04-18(六)14:23:44
ID:WQ5KAon
(PO主)
[
举报
]
No.68507344
管理
管理 -> No.68507344
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
分享图片
…
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-04-20(一)11:02:40
ID:WQ5KAon
(PO主)
[
举报
]
No.68517527
管理
管理 -> No.68517527
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
分享图片
…
无标题
无名氏
2026-04-21(二)16:18:58
ID:WQ5KAon
(PO主)
[
举报
]
No.68524220
管理
管理 -> No.68524220
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
今天下雨了,外面雨声凉凉的好舒服,开始背单词(〃∀〃)
…
无标题
无名氏
2026-05-25(一)17:22:12
ID:WQ5KAon
(PO主)
[
举报
]
No.68711734
管理
管理 -> No.68711734
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
前些天忘记打卡了!但是也有在复习!
今天开文学理论(´゚Д゚`)
…
无标题
无名氏
2026-06-04(四)08:40:54
ID:WQ5KAon
(PO主)
[
举报
]
No.68776172
管理
管理 -> No.68776172
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
目前把专业课放了一下,全力复习六级中
( ´_ゝ`)
用的晓燕老师的急救班,谁来救救我的汉译英
无标题
无名氏
2026-03-24(二)15:27:25
ID:9NMDJFS
[
举报
]
[
订阅
]
No.68351496
[
回应
]
管理
管理 -> No.68351496
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
前略中略后略总之备战考研(`・ω・)
回应有 55 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
无名氏
2026-05-19(二)21:35:12
ID:9NMDJFS
(PO主)
[
举报
]
No.68674231
管理
管理 -> No.68674231
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
day57
社会整理完一章,测量结束,还有三章左右内容需整理
复习专业英语,太专业了给我看晕了要
明天除了实验以外的预定就是复习,看情况增加其他内容
…
无标题
无名氏
2026-05-20(三)21:26:57
ID:9NMDJFS
(PO主)
[
举报
]
No.68681174
管理
管理 -> No.68681174
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
day58
复习得差不多了,不如说再看就要力尽倒下了,今天一天看了平常两周的量|ー` )
好想回家躺着|д` )
…
无标题
无名氏
2026-05-26(二)21:47:22
ID:9NMDJFS
(PO主)
[
举报
]
No.68719837
管理
管理 -> No.68719837
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
day59-day64
临期末有点忙呢,上周四考试,周五到处跑了一天,周六力尽倒下,周六周天也没干很多事(;´Д`)太热力
总之今天整理了一章测量,看了一节马原(虽然之前就学过了,但中间放了很久姑且复习)
练了两页半字,写字好难
还把实验的图和记录弄了一下,明天最后一次实验,收个尾就结束!
另外下周有考试,还需要花时间复习(*´д`)
…
无标题
无名氏
2026-05-28(四)21:52:17
ID:9NMDJFS
(PO主)
[
举报
]
No.68734045
管理
管理 -> No.68734045
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
day65-66
昨天做完实验回家直接一觉睡到快十一点(´゚Д゚`)
今天是一节社会,整理测量,做了马原导论的习题
今天早点歇了,明天还要出门( ゚ 3゚)
…
无标题
无名氏
2026-06-03(三)23:36:22
ID:9NMDJFS
(PO主)
[
举报
]
No.68774964
管理
管理 -> No.68774964
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
day67-72
考完了,下一门要到月底,其他杂七杂八的任务也解决了,明天应该能恢复学习
无标题
无名氏
2025-12-06(六)19:03:36
ID:ZnXSArB
[
举报
]
[
订阅
]
No.67580410
[
回应
]
管理
管理 -> No.67580410
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
极限零基础备考英语三级,
从背单词开始(つд⊂)
回应有 164 篇被省略。要阅读所有回应请按下回应链接。
…
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-05-30(六)23:01:09
ID:WdRvBFx
[
举报
]
No.68746887
管理
管理 -> No.68746887
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
分享图片
…
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-05-31(日)17:27:11
ID:WdRvBFx
[
举报
]
No.68750898
管理
管理 -> No.68750898
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
分享图片
…
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-06-01(一)16:59:39
ID:WdRvBFx
[
举报
]
No.68757423
管理
管理 -> No.68757423
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
分享图片
…
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-06-02(二)17:02:44
ID:WdRvBFx
[
举报
]
No.68764862
管理
管理 -> No.68764862
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
分享图片
…
收起
查看大图
向左旋转
向右旋转
无标题
无名氏
2026-06-03(三)17:19:33
ID:WdRvBFx
[
举报
]
No.68772602
管理
管理 -> No.68772602
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
分享图片
考研+减肥打卡
德布罗意菠萝吹雪
2026-05-15(五)19:51:55
ID:O1LcKxp
[
举报
]
[
订阅
]
No.68650553
[
回应
]
管理
管理 -> No.68650553
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
总而言之,言而总之,这是肥的二战。去年一共学了四个月,也没听课,也没报班,就一个人闷头学,考了290分。跟家里人商量了一下,觉得再来一次上岸理想院校的概率还是比较大的,所以今年肥一个人租了个小房子,在附近的自习室租了工位,开始每天学习。现在已经学了两周,生活上的一些琐事也都安排好了。稳定下来后,决定开一个打卡记录串,让自己能够多一些韧性。
回应有 3 篇被省略。要阅读所有回应请按下回应链接。
…
无标题
无名氏
2026-05-18(一)21:25:39
ID:O1LcKxp
(PO主)
[
举报
]
No.68667965
管理
管理 -> No.68667965
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
>>No.68650573
感谢肥哥!(*゚∇゚)
…
无标题
无名氏
2026-05-20(三)22:16:11
ID:O1LcKxp
(PO主)
[
举报
]
No.68681538
管理
管理 -> No.68681538
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
5.20
这几天过得不是很好,连着两天晚上失眠,我早上起来背单词都能背睡着过去。好在学习没有耽误太多,把张宇第二讲的课和题都刷完了,单词也没有落下。
现在正在借着三天一次的做饭时间给家教的学生备课。话说现在的高考卷子也太难了吧,我本科都毕业了做个高考数学卷子还是经常觉得匪夷所思。
希望今晚能把两个数学的家教都备课完成,这样周四捎带手就可以给英语的备完,不会影响周四周五周六的刷课。
以上。
…
无标题
无名氏
2026-05-22(五)00:15:43
ID:O1LcKxp
(PO主)
[
举报
]
No.68689207
管理
管理 -> No.68689207
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
写在5.21的5.20总结
今天早起体重112.6公斤,又回落了。
依旧复习100,背新词200。
数学方面,今天听完了张宇的第三讲,明天把题做了。
备课还差一点,明天刷完题顺便完成。
明天准备开一线代,今天算了一下我想要追上进度还是要再下功夫。
困死了,睡觉。
…
无标题
无名氏
2026-05-25(一)22:36:48
ID:O1LcKxp
(PO主)
[
举报
]
No.68713490
管理
管理 -> No.68713490
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
5.25
周六日太累了,上了三堂家教,又骑车了十八公里,精神肉体的双重折磨,实在是太累了。
今天周一,醒来的时候已经九点多了,然后又堕落地睡过去了。
下午两点钟开始学,背了一个小时的单词,然后听了五个小时的数学,给线性代数第一讲听了一半,高数第三讲听完了。
明天的打算是上午刷完高数第三讲的题,然后下午听六个小时的课,把线代第一讲听完,高数第四讲听一部分。
睡觉了,明天争取能学九个小时以上。
…
无标题
无名氏
2026-06-03(三)09:39:25
ID:O1LcKxp
(PO主)
[
举报
]
No.68769663
管理
管理 -> No.68769663
SAGE
编辑
查询
Cookie查询
锁Cookie
删串
6.3
额啊,前几天太忙太累以至于没有空更串记录了。总而言之是开始尝试把每天的学习时间拉长到十一个小时,结果是每天睡觉跟昏迷了一样。
锻炼的话,每天都有在运动,总步数甚至能到一万五左右,但是踏马的体重就是不怎么掉,可能是我现在吃的有点多?还是说压力大皮质醇分泌然后体重不会掉?无所谓了,这件事是需要长期来办的。
最近开始想着去健身房跑步,暂定一周一次,作为疏导压力的发泄。
学习的进度的话,目前准备这个月之内完成高数的基础,线性代数做到差一章。正在努力实现中。
首页
上一页
3
4
5
下一页
UP主:







{kind=link}